By default, Whisper generates long subtitles depending on the transcribed results. If you want to use them for traditional videos or films, it could be just fine. However, short duration videos like the ones we can find in Youtube, TikTok or Instagram are normally vertical oriented and subtitles tend to be way shorter to not fill the whole screen with words. Also, they tend to be impactful and simple, sharing a really specific message or idea. For those kinds of videos, fewer words on the screen can be more dynamic and less intimidating for the watcher.
Let’s start with a brief introduction about Whisper.
What is Whisper?
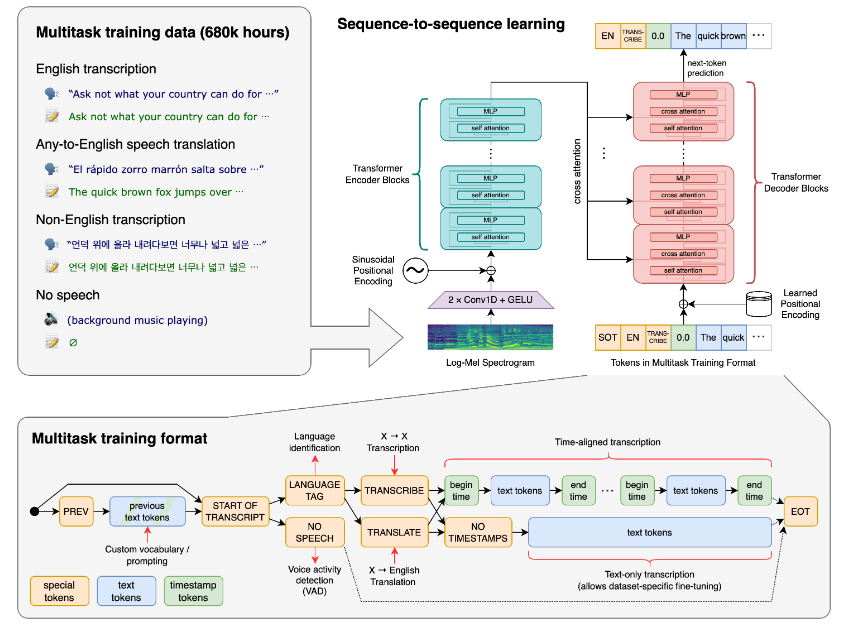
Whisper is an AI model for speech recognition. It supports a lot of languages that can be automatically detected or set up from the beginning. Released by OpenAI (creators of ChatGPT), this model is completely free of use as it’s signed under MIT license.
You can find the source code in the public repository in Github: https://github.com/openai/whisper
How to generate subtitles with Whisper?
Generating subtitles with Whisper is straightforward. You will need to install it following the README instructions and use it from the CLI or directly using the Whisper Python model in a script.
Using CLI whisper test.wav --model base
import whisper
from whisper.utils import get_writer
# Load the model and transcribe the audio
model = whisper.load_model('base')
audio = whisper.load_audio("test.wav")
result = whisper.transcribe(model, audio)
# Save the results as a SRT file
srt_writer = get_writer("srt", ".")
srt_writer(result, "test.wav")
You can generate subtitles with .srt, .tsv and .vtt formats.
How to reduce the lenght of subtitles using Whisper?
You can feel that the subtitles that Whisper generated have not the best size for your videos. Finding the best sizing depends on many things: the language transcribed, the video format or the speech speed. In order to customize the size of the subtitles, you will need to play with the word options.
The first way is to use max_line_width along with max_line_count:
Using CLI whisper test.wav --model base --word_timestamps True --max_line_width 42 --max_line_count 1
import whisper
from whisper.utils import get_writer
model = whisper.load_model('base')
audio = whisper.load_audio("test.wav")
result = whisper.transcribe(model, audio, word_timestamps=True)
# Save as an SRT file
srt_writer = get_writer("srt", ".")
srt_writer(result, "test.wav", {"max_line_width":42, "max_line_count":1})
This will fix a maximum number of characters and subtitle lines that we want to display at one moment. Although the length of subtitles is accurate with this option, you cannot predict how many words they are going to fit in there. Also, subtitles join the end of sentences with the beginning of new ones, so sometimes subtitles can be hanging in there for quite some time.
From release v20231106, you can find a new word option called –max_word_per_line that, as the name explains, will fix the maximum number of words you will see in a subtitle line:
Using CLI whisper test.wav --model base --word_timestamps True --max_words_per_line 3
import whisper
from whisper.utils import get_writer
model = whisper.load_model('base')
audio = whisper.load_audio("test.wav")
result = whisper.transcribe(model, audio, word_timestamps=True)
# Save as an SRT file
srt_writer = get_writer("srt", ".")
srt_writer(result, "test.wav", {"max_words_per_line":3})
From my experience, subtitles generated using this option are more pleasant compared with the results I obtained using –max_line_width. You can check the comparison of subtitles generated with and without these options:
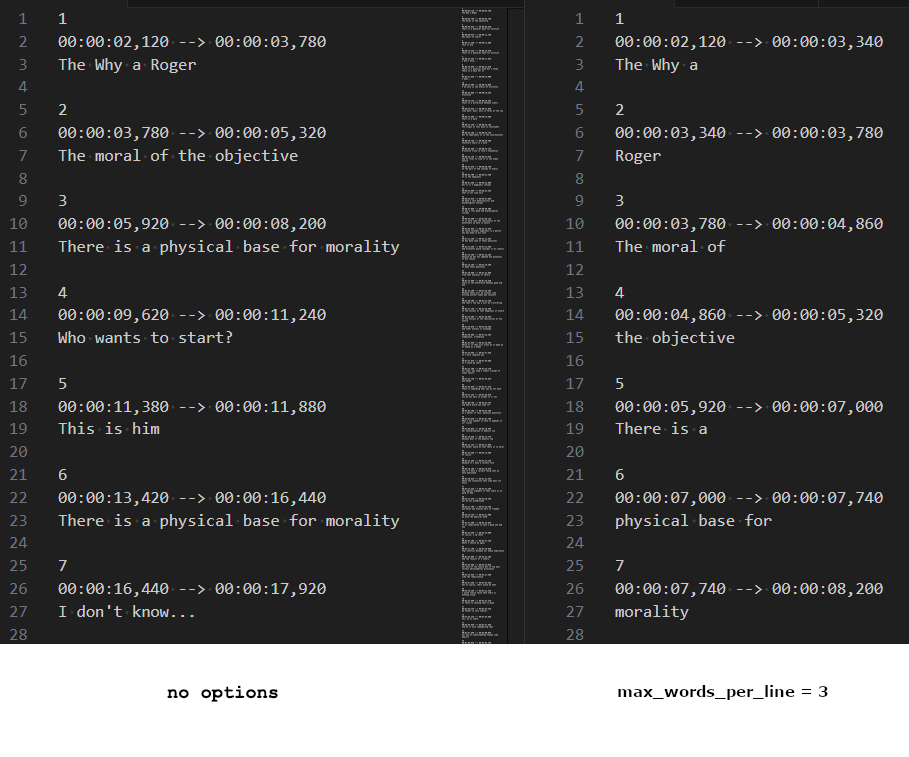
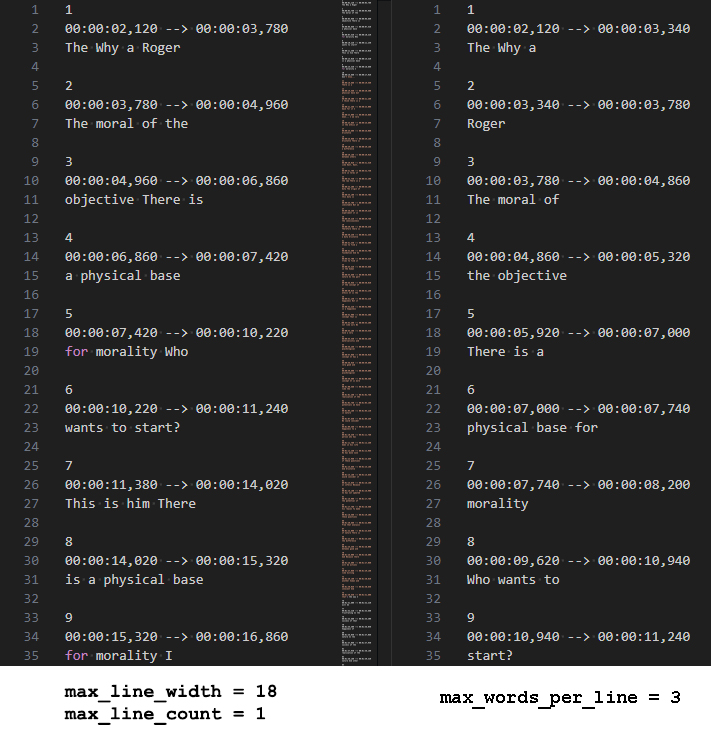
If you need more information about –max_word_per_line, check this PR.
Hi! My name is Alejandro and I’m Technical Lead (Full-Stack). I’m really interested on new technologies and programming skills. I also participated in some gaming development competitions. I hope you enjoy this blog! 😉